![]()
©2022 by FeynmaTechnology
![]()
©2022 by FeynmaTechnology
2025.9.12
ブファイマテクノロジーの堀江です。
今回は生成AIを用いた当社の研究内容について、紹介します。
なお今回のメイン研究は当社の佐藤さんが行ってくれています。
テーマはこちらです!
「机の上に積まれた論文たちが、もし夜のあいだに内緒でディスカッションを始めて、朝には「ここ、つながってるよ」とメモを残してくれたら——。」
これは派手な魔法ではなく、生成AIの技術を用いた「創発(emergence)」です。
近年、科学研究は前例のない速度で進み、論文は爆発的に増え続けています。しかし、知識は分野の壁に閉じこもり、横断的につながらないまま眠っていることが少なくありません。
もし複数の論文を機械的に処理・統合し、論文間の関係性を地図のように浮かび上がらせる仕組みがあったなら——そこから、人間の「気づき」に匹敵する創発(emergence)が生まれる可能性はあるのでしょうか。
人間の「気づき」に関する一例を上げます。
私たちが自販機で同じコインが何度も戻ってくると「これは読み取れないコインだ」と自然に悟るように、データの総和を超えた意味の飛躍はたしかに存在します。LLMが単独でこの力を完全に示すのはまだ難しいとしても、膨大な知識を横断的に統合する設計が整えば、創発に等価な力が静かに立ち上がる——本稿はその前提に立ち、複数の論文を対象にした知識統合処理という視点から、「何が課題か」「どう進めるか」「その先に何が起きるか」を整理してご紹介します。

研究の最前線では、特に医学やAI分野を中心に成果が日々更新され、すべてを読み、横断的に理解し続けることは現実的に困難になっています。この状況は、分野ごとに知が積み上がる一方で分野間の接続が見えにくくなるという、いわば「見えない壁」を生みます。例えば、AIの言語モデルと医学の画像診断支援は一見遠い領域に見えますが、学習データの設計や解釈性(Explainability)といった観点では共通する課題と示唆を多く持っています。それでも、論文が個別の山として積み上がるだけでは、隣の山から伸びているはずの橋が見えず、重要なヒントが静かに取りこぼされていきます。
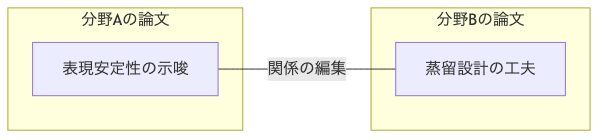
ここからは、具体的にどう手を動かすかをご一緒に見ていきましょう。結論から言うと、やることは「意味の単位でほぐし、意味の単位でつなぐ」です。
このプロセスにより、同じテーマがまとまるだけでなく、遠い分野同士の思わぬ橋渡しが生まれます。たとえば小規模LMの表現安定性の示唆と、医用画像の蒸留設計の工夫がつながると、データが限られた環境でも安定して学習できる設計指針が見えてきます。大事なのは、キーワードの一致ではなく、文脈の「息づかい」を捉えることです。
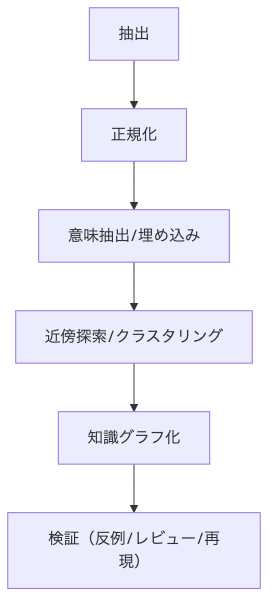
少し立ち止まって、創発のイメージを共有させてください。創発(emergence)は、個々の断片を足し合わせても出てこない性質が、つなぎ方を工夫した瞬間に現れることです。離れていた領域がふと握手する、名前のなかった仮説が輪郭を帯びる——その源は「関係のつくり方」にあります。量を増やすことより、関係の設計が変わることが、次の一歩の方向を更新します。
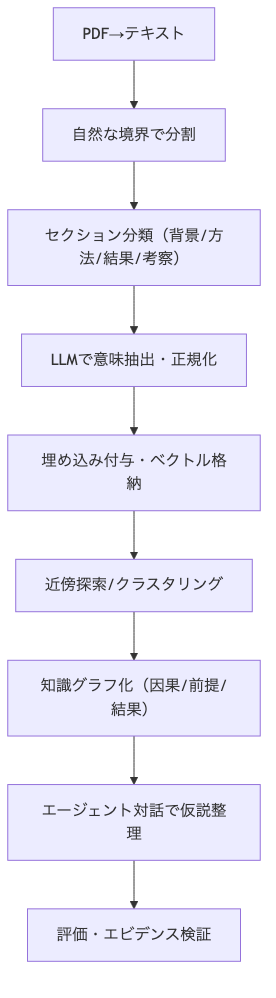
いよいよ実装です。難しく考えすぎず、手順を小さく分けて始めましょう。PDFをテキスト化し、自然なまとまりで分割、セクションの位置づけを明確にします。次に、LLMで意味を抽出し、断片に埋め込み(embedding)を付与して検索・クラスタリング・知識グラフ化につなげます。
加えて、マルチエージェントの「バーチャルディスカッション」で収束点と対立点を洗い出し、引用や根拠のトレースを保ちます。ここでのLLMは「答える装置」ではなく、「関係を生み、人が確かめられる形に整える編集者」として働きます。
AIの活用で評価は大切なところです(そして難しいところです)。なんとなくの手触りの良さだけで判断せず、ひとつの見方に偏らないで、いくつかの視点から確かめます。専門家が文脈の妥当性を確認し、実験・臨床・実装で再現性を検証することに加え、次の点を数値でも見ていきます。
これらが整ってくるほど、成果はレビュー支援の域を超え、政策づくりや医療プロトコル、環境設計など「説明できて再現できること」が大切な場面にも、自然につながっていきます。
最後に「なぜ、今、知識統合なのか」を振り返ります。
先端分野の研究では論文は増え続け、断片のままでは接点が見えません。だからこそ、断片を拾い、意味でつなぎ直し、分野という境界に小さな突破口を作る必要があります。
知識統合とは、単なる要約や効率化ではなく、見えない接点を示唆する試みです。生成AIは、言葉を文言ではなく意味の流れを扱う道具として用いることで、探したいこと、研究したいことを広げていくことができます。
ここまでの話をひとことで言えば ——情報の関係の編集が新しい気づきを呼び込むことができるということです。
複数論文の機械的処理と知識統合は、レビューの迅速化にとどまらず、人の「気づき」に近い創発的な新知を育てます。丁寧な抽出と再統合、そして確かな評価を通じて、研究・開発の現場で、説明できて再現できる判断を後押しできるかもしれません。
import pandas as pd
import streamlit as st
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
import openai
import os
import pandas as pd
import streamlit as st
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import datetime
import csv
import codecs
import json
import pytz
from tqdm import tqdm
# 記事を生成
article = []
import os
import boto3
import json
from typing import Dict
from typing import Annotated, List, TypedDict
import operator
#st.write(paper_infos)
SPEAKERS_NAMES = {
'A子': {"担当論文一覧": "BERT"},
'B太': {"担当論文一覧": "BERT"}
}
class AppState(TypedDict):
thema: str
history: Annotated[List[str], operator.add]
speak_count: int
next_speaker: str
conversation_summary: str
user_end: bool
# セッションステートの初期化
if 'thema' not in st.session_state:
st.session_state.thema = "与えられた論文をもとにして3つの新しいアイデアを創出してください。"
if 'history' not in st.session_state:
st.session_state.history = []
if 'speak_count' not in st.session_state:
st.session_state.speak_count = 0
if 'next_speaker' not in st.session_state:
st.session_state.next_speaker = None
if 'conversation_summary' not in st.session_state:
st.session_state.conversation_summary = ""
if 'user_end' not in st.session_state:
st.session_state.user_end = False
if 'chat_log' not in st.session_state:
st.session_state.chat_log = []
import random
# Anthropic Model Setup
claude_client = boto3.client(
"bedrock-runtime", region_name="us-east-1" # 適切なリージョンを指定
)
def invoke_claude(prompt: str) -> str:
"""
Claude-3 モデルを呼び出すためのヘルパー関数
Args:
prompt (str): モデルへのプロンプト
Returns:
str: Claudeからのレスポンス
"""
bedrock_client = boto3.client(
"bedrock-runtime",
region_name="us-east-1" # 適切なリージョンを指定
)
# フォーマットに沿ったプロンプトを生成
prompt = f"""
Human: {prompt}
Assistant:"""
messages = [
{"role": "user", "content": [{"text": prompt}]}
]
# Converse APIの呼び出し
response = bedrock_client.converse(
modelId="anthropic.claude-3-5-sonnet-20240620-v1:0",
messages=messages,
inferenceConfig={
"maxTokens": 1000 # トークンの最大数を設定
}
)
# レスポンスの解析
assistant_reply = response["output"]["message"]["content"][0]["text"]
return assistant_reply
def speaker(state: AppState):
"""
会話の参加者として発言を生成します。
Args:
state(AppState): AppState
Return:
Dict[str]: 生成した発言
"""
print("speaker")
speaker_name = st.session_state.next_speaker
history = st.session_state.history
thema = st.session_state.thema
speak_count = st.session_state.speak_count
system_message = f"""あなたは次のようなパーソナリティを持った人物です。
------------
{speaker_name}
------------
あなたが担当する論文は以下のとおりです。
{SPEAKERS_NAMES[speaker_name]["担当論文一覧"]}
この人物"{speaker_name}"として他の参加者と{thema}について会話をし、全員で結論を出してください。
"""
human_message_prefix = f"""あなたは今{thema}について他の参加者と会話をし、全員で結論を導くタスクが与えられています。
これまでの会話の履歴を見て、あなたの{thema}についての意見を自然な短い文体で作成してください。
ただし、以下の点に留意してください。
・各論文の技術的特徴を踏まえてなるべく具体的な意見を述べることも意識してください。
・また、情報を捕捉するような会話を心がけてください。
・分からないところがあれば、発言の終わりに問いを生み出すようにしてください。
・与えられた論文の内容を根拠とした建設的な会話を心がけてください。
・良いアイデアが出ている時は実現方法など詳細な議論を深めるようにしてください。
・アイデアは一つずつ出して議論を深めてください。
# 会話の履歴
"""
print(history)
human_message = human_message_prefix + "\n".join(history) + f"\n{speaker_name}: "
response_text = invoke_claude(system_message + "\n" + human_message)
st.session_state.chat_log.append({"name": speaker_name, "msg": response_text})
st.session_state.history.append(f"{speaker_name}: {response_text}")
st.session_state.next_speaker = speaker_name
st.session_state.speak_count = speak_count + 1
return {
"history": [f"{speaker_name}: {response_text}"],
"speak_count": speak_count + 1
}
def conversation_manager(state: AppState):
"""
会話の管理者として次の発言者を決定します。
Args:
state(AppState): AppState
Return:
Dict[str]: 次の発言者の名前
"""
print("conversation_manager")
max_speak_count = 9 # 会話の回数の最大値
first_speaker_index = 0 # 一番最初の発言者のindex
speak_count = st.session_state.speak_count
history = st.session_state.history
thema = st.session_state.thema
user_end = st.session_state.user_end
greeting_msg = f"""司会: 今日は[{thema}]についてのみなさんの活発なご意見を聞かせて下さい!"""
speakers_names_str = ",".join(SPEAKERS_NAMES .keys())
if user_end:
print("no_one")
st.session_state.next_speaker = "no_one"
return {"next_speaker": "no_one"}
# if speak_count == 0:
# return {"history": [greeting_msg], "next_speaker": list(SPEAKERS_NAMES[first_speaker_index].keys())[0]}
system_message = f"""{speakers_names_str}が{thema}についての会話をしています。
あなたはこの会話を管理する役割を持っています。
与えられる会話の履歴を読み、次に発言すべき参加者の名前を決定します。"""
print(speak_count)
if speak_count%3 != 2:
human_message = f"""これまでの{thema}についての[{speakers_names_str}]の履歴を見て、
会話の結論がまとまるまで次に誰が発言すべきかを決めて下さい。
連続で同じ人に発言させないようにしてください。
必ず一人2回以上発言させるようにしてください。
同じような内容の会話が連続しこれ以上会話に変化が見られないと判断した場合は[TERMINATE]と出力してください。
それ以外は必ず[{speakers_names_str}]のどれかを出力してください。
# 履歴
{st.session_state.history}
次の発言者:
"""
response_text = invoke_claude(system_message + "\n" + human_message)
#st.write(response_text)
generate_text = response_text.split("\n")[0]
if generate_text in speakers_names_str.split(','):
st.session_state.next_speaker = generate_text
return {"next_speaker": generate_text}
elif "TERMINATE" in generate_text:
st.session_state.next_speaker ="user"
return {"next_speaker": "user"}
else:
st.session_state.next_speaker ="user"
return {"next_speaker": "user"}
def user_comment(state: AppState):
print("user")
speak_count = st.session_state.speak_count
# チャットログの初期化
if "chat_log" not in st.session_state:
st.session_state.chat_log = []
# 初回の呼び出し時に入力待ちフラグをセット
if "user_comment_active" not in st.session_state:
st.session_state.user_comment_active = True
# ユーザーに質問を表示
# st.write("ここまでの会話で気になる点はありますか?特になく会話を終わらせる場合は END と入力してください。")
# 過去のチャットログを表示
for chat in st.session_state.chat_log:
with st.chat_message(chat["name"]):
st.write(chat["msg"])
# ユーザーに質問を表示
st.write("ここまでの会話で気になる点はありますか?特になく会話を終わらせる場合は END と入力してください。")
# ユーザー入力を取得(固定の key を使用)
comment = st.chat_input("文字を入力してください:", key=f"user_chat_input{speak_count}")
print(comment)
# 入力がない場合は `st.stop()` で待機
if comment is None:
st.stop()
# 入力完了後に `user_comment_active` を False にして、入力欄を消す
st.session_state.user_comment_active = False
# 入力されたコメントを表示
USER_NAME = "user"
with st.chat_message(USER_NAME):
st.write(comment)
print(comment)
# チャットログに追加
st.session_state.chat_log.append({"name": USER_NAME, "msg": comment})
# "END" が入力された場合、会話を終了
if comment == "END":
st.session_state.user_end = True
st.session_state.speak_count += 1
print("end")
return {"user_end": True, "speak_count": st.session_state.speak_count}
# セッションの履歴とカウントを更新
st.session_state.history.append(f"User: {comment}")
st.session_state.speak_count += 1
return {"history": [f"User: {comment}"], "speak_count": st.session_state.speak_count}
def conversation_summarizer(state: AppState):
"""
会話の最後に会話の内容を要約し、インサイトを作成します。
Args:
state(AppState)
Return:
Dict[str]: 生成した会話から得られるインサイト
"""
history = st.session_state.history
thema = st.session_state.thema
system_message = "あなたは複数人の会話から有益なインサイトを見つけることに長けています。"
human_message = f"""これまでの"{thema}"についての会話の履歴を見て素人でもわかるように3つの主要なアイデアについてまとめて詳しく説明してください。
# 履歴
{st.session_state.history}
"""
response_text = invoke_claude(system_message + "\n" + human_message)
#st.write(response_text)
st.session_state.conversation_summary = response_text
return {"conversation_summary": response_text}
def next_speaker(state: AppState):
"""
次の発言者を決めます。
Args:
state: AppState
Return:
str: 次のアクション
"""
speaker_name = st.session_state.next_speaker
speakers_names_str = ",".join(SPEAKERS_NAMES .keys())
print("A")
print(speaker_name)
if speaker_name in speakers_names_str.split(','):
# 次の発言者が指定された場合
return "continue"
elif speaker_name == "user":
return "comment"
else:
# 会話が完了した場合
return "summarize"
## 新しいクエリの作成
new_query = f'''与えられた論文をもとにして3つの新しいアイデアを創出してください。アプリケーションよりも基礎研究よりのアイデアが欲しいです。'''
from langgraph.graph import END, StateGraph
workflow = StateGraph(AppState)
workflow.add_node("conversation_manager", conversation_manager)
workflow.add_node("speaker", speaker)
workflow.add_node("user_comment", user_comment)
workflow.add_node("conversation_summarizer", conversation_summarizer)
workflow.add_conditional_edges(
"conversation_manager",
next_speaker,
{
"continue": "speaker",
"comment": "user_comment",
"summarize": "conversation_summarizer",
}
)
workflow.add_edge("speaker", "conversation_manager")
workflow.add_edge("user_comment", "conversation_manager")
workflow.add_edge("conversation_summarizer", END)
workflow.set_entry_point("conversation_manager")
group_discussion = workflow.compile()
st.write(group_discussion.get_graph().draw_mermaid())
if "chat_log" not in st.session_state:
st.session_state.chat_log = []
discussion_history = group_discussion.invoke({
"thema":f"{new_query}",
"speak_count": 0,
"history":[],
"next_speaker": None,
"conversation_summary": "",
"user_end": False
})
print("###history###")
print(discussion_history["history"])
summary = discussion_history["conversation_summary"]
st.write(summary)
大規模言語モデルは世界中で日々研究が行われており、ファイマテクノロジーでは、お客様のニーズに合わせて業務効率化や生産性向上のソリューション開発を行っています。AIやソフトウェアを活用した業務効率化や生産性向上をご検討中の方は、ぜひファイマテクノロジーにご相談ください。

![]()
CONTACT

| 会社名 | 株式会社Feynma Technology |
|---|---|
| 所在地 | 〒461-0005 愛知県名古屋市東区東桜一丁目1番1号 アーバンネット名古屋ネクスタビル内スモールオフィス |
| 設立 | 2020年4月1日 |
| 代表者 | 土屋太助 |
| 資本金 | 2,000万円 |
| 従業員数 | 17名 |
| 事業内容 | AI活用のコンサルティングおよび 分析プラットフォームの開発、販売 |