
論文PDFデータ抽出ソリューション
生成AI開発を加速。
PDF論文から
高品質データを抽出。
 issue
issue
生成AI開発に質の良いデータ、
足りていますか?
生成AI開発の成否を左右する最重要factor、それはデータの質です。しかし、専門性の高い論文PDFからの高品質データ抽出は、多くの研究機関や企業にとって大きな壁となっています。
-

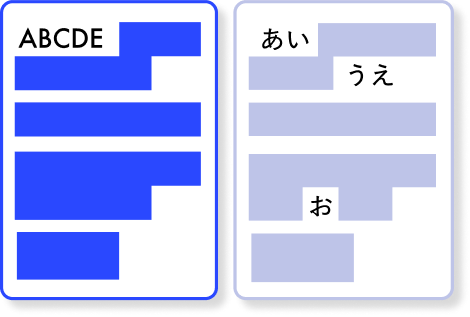
テキスト抽出が
バラバラ -


分断された
テキストの文脈が失われる -


画像ベースの文書から
テキストが抽出できない。
solution
1extractが提供する
ソリューション
ファイマテクノロジーが提供する“1extract”は、PDF論文翻訳AI“1paper”で開発した「PDF抽出エンジン」を元にしています。
高精度で構造を保持したデータ抽出により、生成AI開発に最適なデータの取得が可能になります。
frature
PDFから段落構造を考慮した
テキストの抽出を行います
テキスト、図表、章題など、論文PDFに含まれる全ての情報を、高品質かつ構造化されたデータとして抽出します。生成AI開発に必要な、あらゆるデータニーズにお応えします。


翻訳品質を支える3つの特徴
-
段組、改ページで分割
された文章の結合 -
図の抽出 &
章題の検出 -
抽出したテキストの
翻訳、言語の統一 ※オプション
PDFデータを活用した
生成AI開発に
お困りではありませんか?



contact
お問い合わせ
